

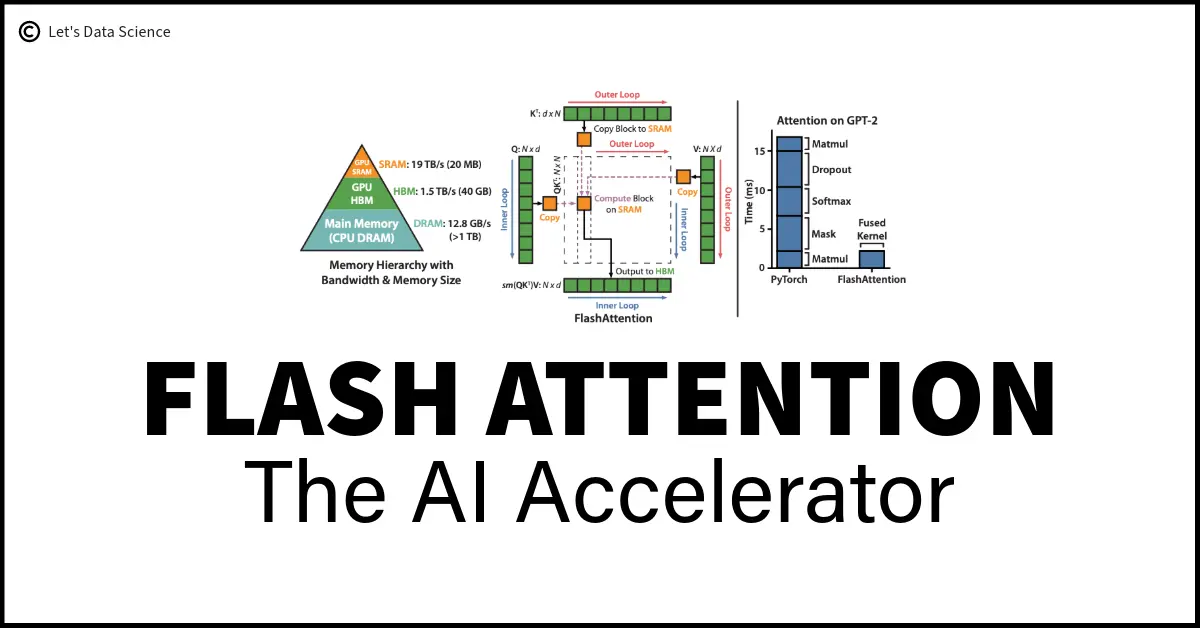
What、Why、Where、How
What: 通过减少IO访问量加速attention计算
Why: Attention计算是memory-bound而非computation-bound
Where: 以往的文章都注重加速计算过程,而本文着力于减少访存消耗
How: 矩阵分块减少中间结果缓存、反向传播时重新计算中间结果
Result: 2-4x speedup, 10-20x memory reduction
arXiv链接:https://arxiv.org/abs/2205.14135
Why we need this?
在一个标准transformer block中,我们执行类似如下的流程
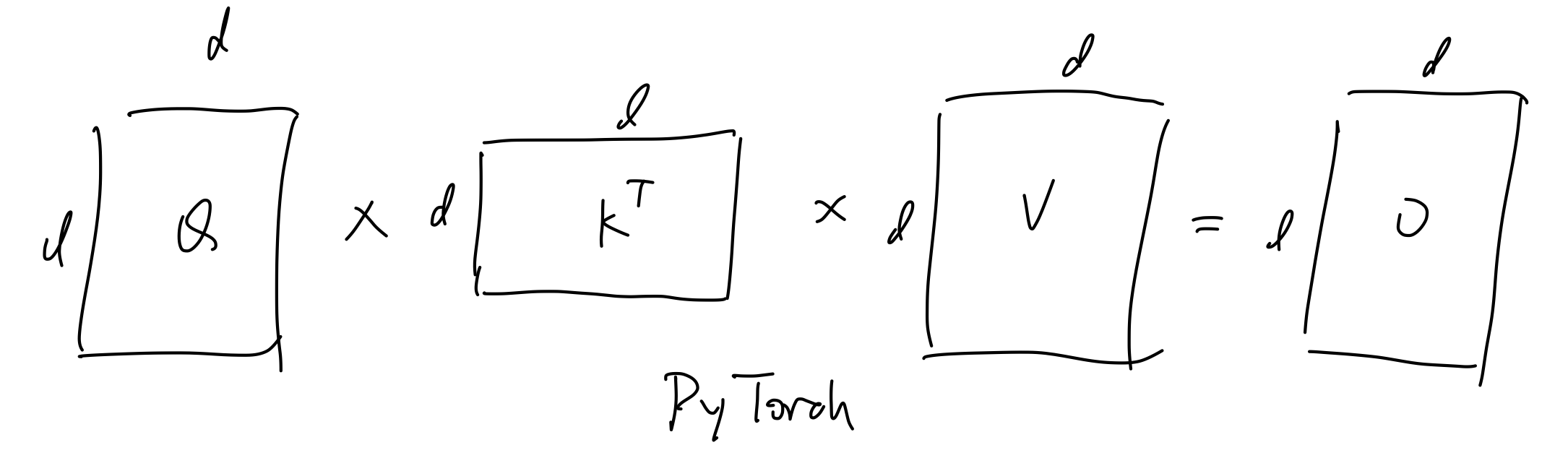
如下图左侧的PyTorch实现版本所示
# l, d: 长度、特征维度
# input: 形状为l*d的输入
# output: 形状为l*d的输出
def attention(input) -> output:
Q = W_Q * input # l*d
K = W_K * input # l*d
V = W_V * input # l*d
att = Q * K.T # l*l
att = sigmoid(att)
att = dropout(att)
out = att * V # l*d
out = W_O * out
return out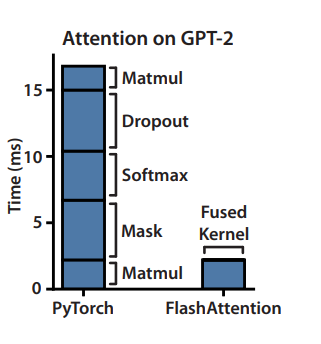
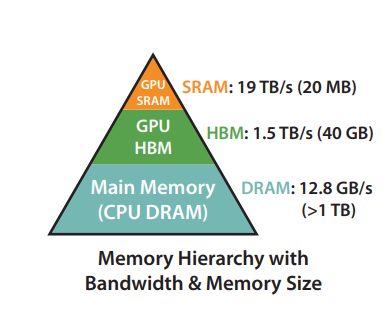
对于后GPT-3.5的模型来说,d和支持的length都很大。
在计算这些矩阵的时候,不可能把他们全放在SBM内存中计算。
需要大量的将数据转移到HBM中来腾出空间计算矩阵这一操作。
而正是这一特性导致attention计算是memory-bound而非computation-bound。
How we achieved this?
If softmax doesn't exist...
拿没有softmax的attention计算过程(假设长度length=15)举例子:
由于矩阵较大,中间结果需多次写入显存再读回,导致IO开销极高。如果我们采用分块矩阵的思想:
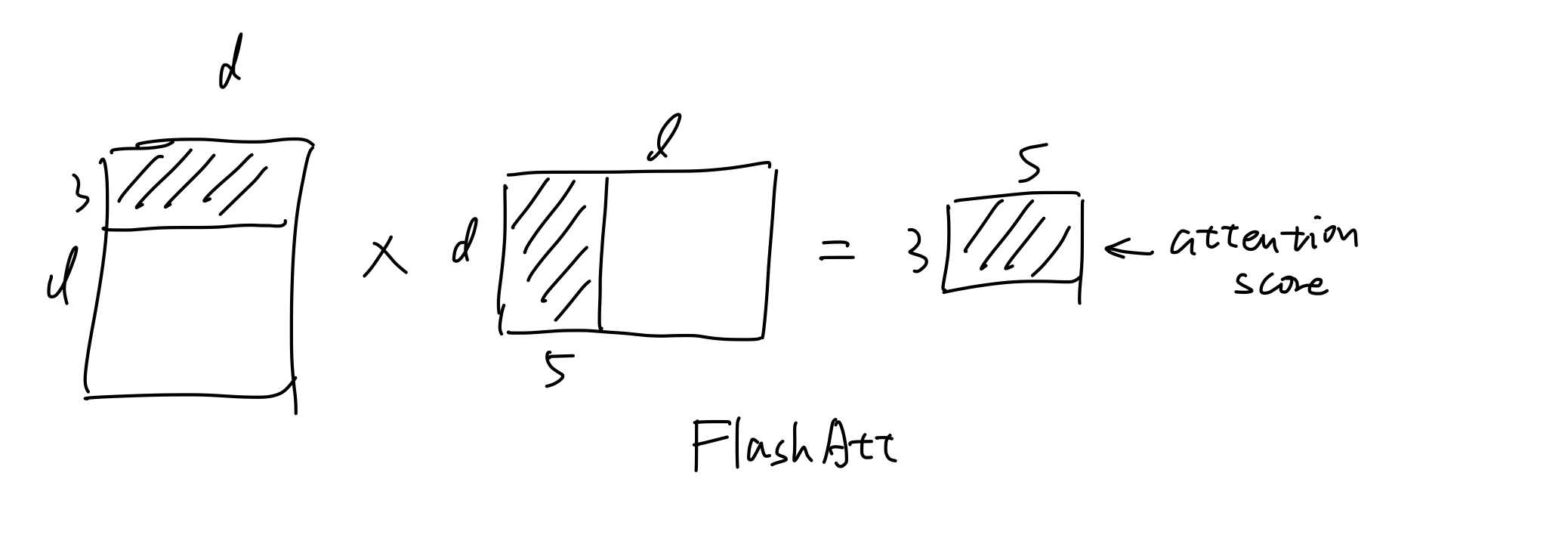
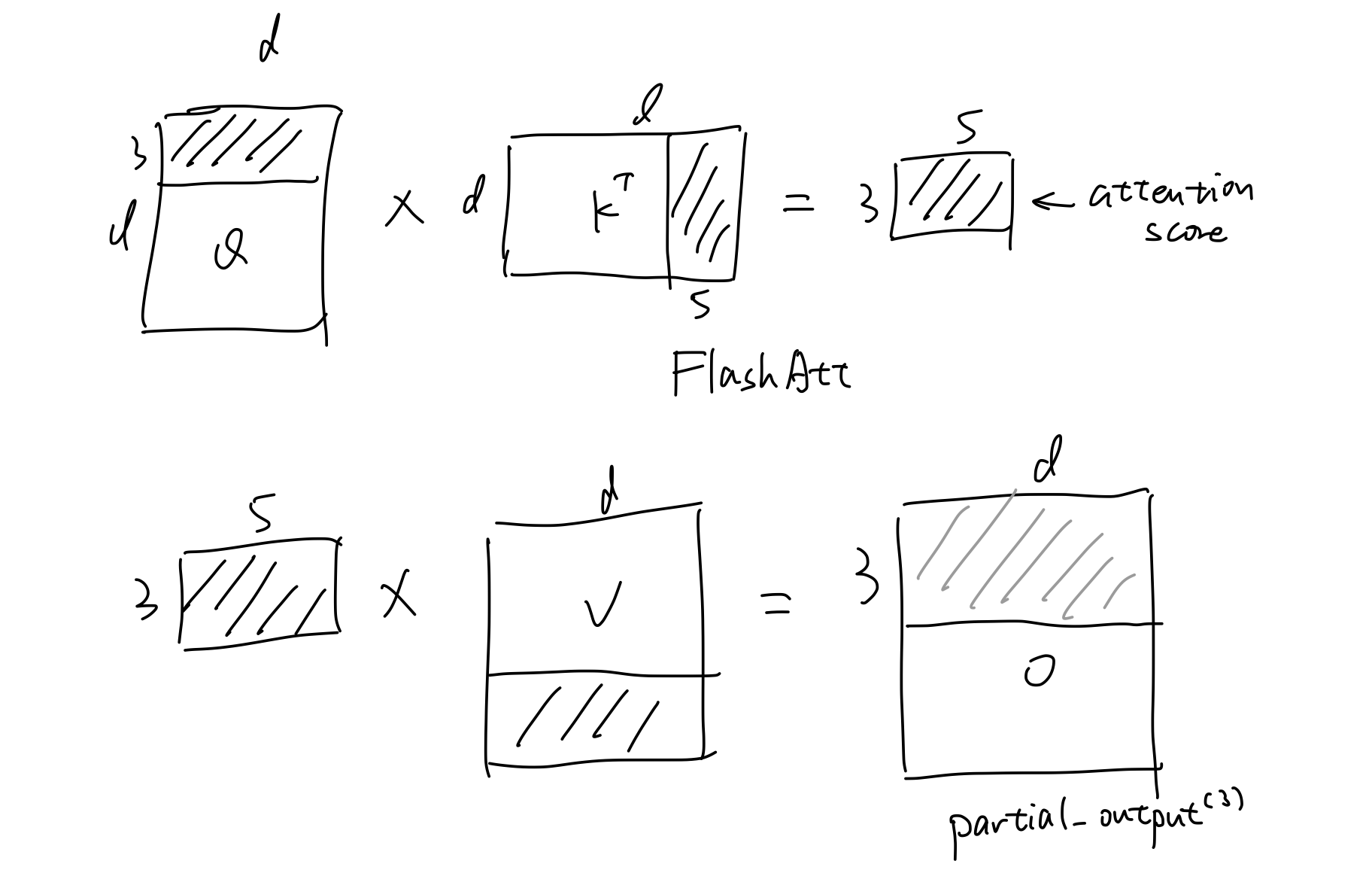
先拿出Q的前3行,KT的前5列,计算部分attention_score。(这个attn_score的物理意义是前3个词与前5个词的注意力分数)
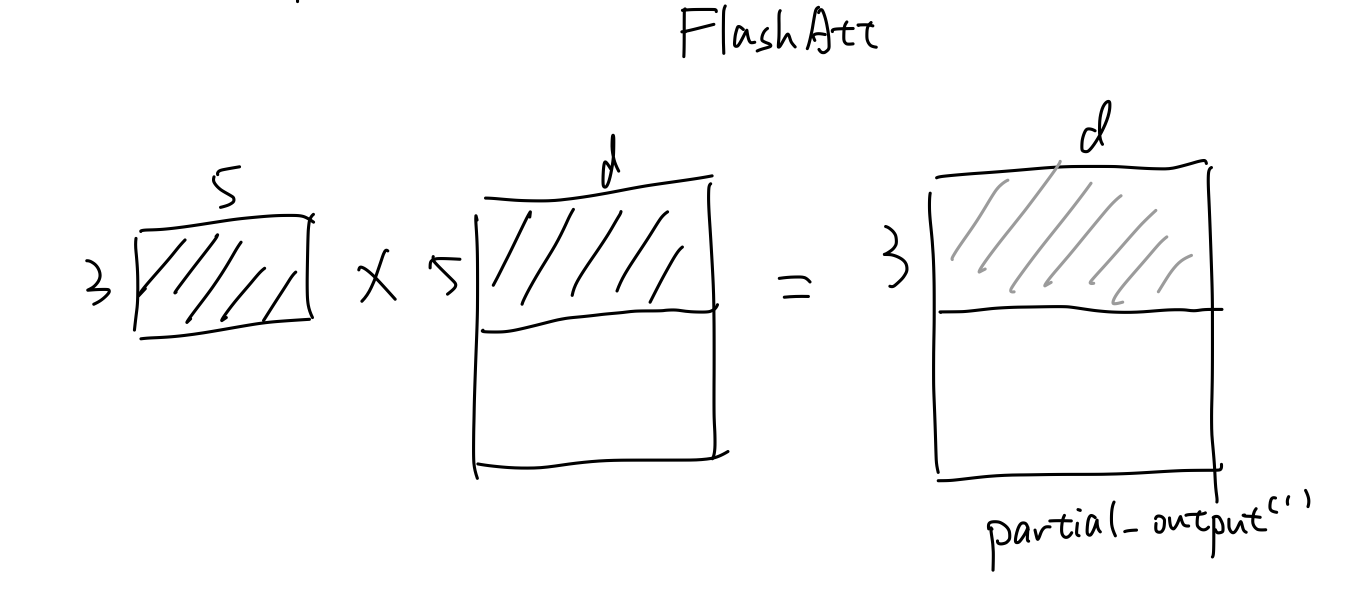
然后用这个attn_score与V的前5行做计算,计算出partial_output(1)。
需要注意的是:
前3个词与前5个词的注意力分数只能与前5个词的V矩阵做计算,得出前三个词每个词与前5个词V的线性组合加和
这意味着得出的结果还剩下前3个词与后10个词的attention_score与矩阵V做计算,而这些结果也需要与目前3*d的结果直接加起来
所以我们称目前的结果为partial_output(1)
剩下的步骤就是类似地计算出partial_output(2)和partial_output(3)
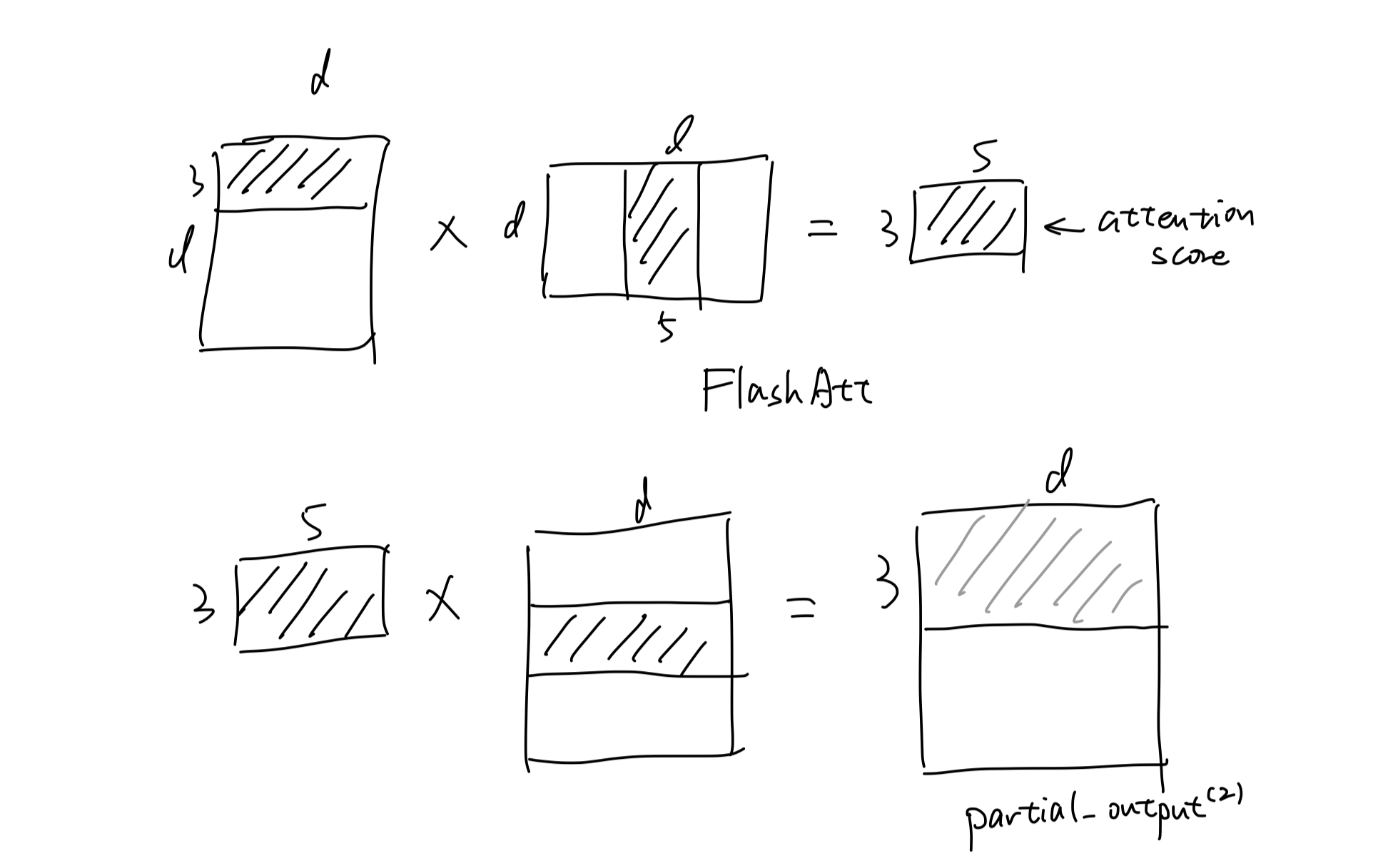
最后得到output地前三行即为partial_output(1)+partial_output(2)+partial_output(3)
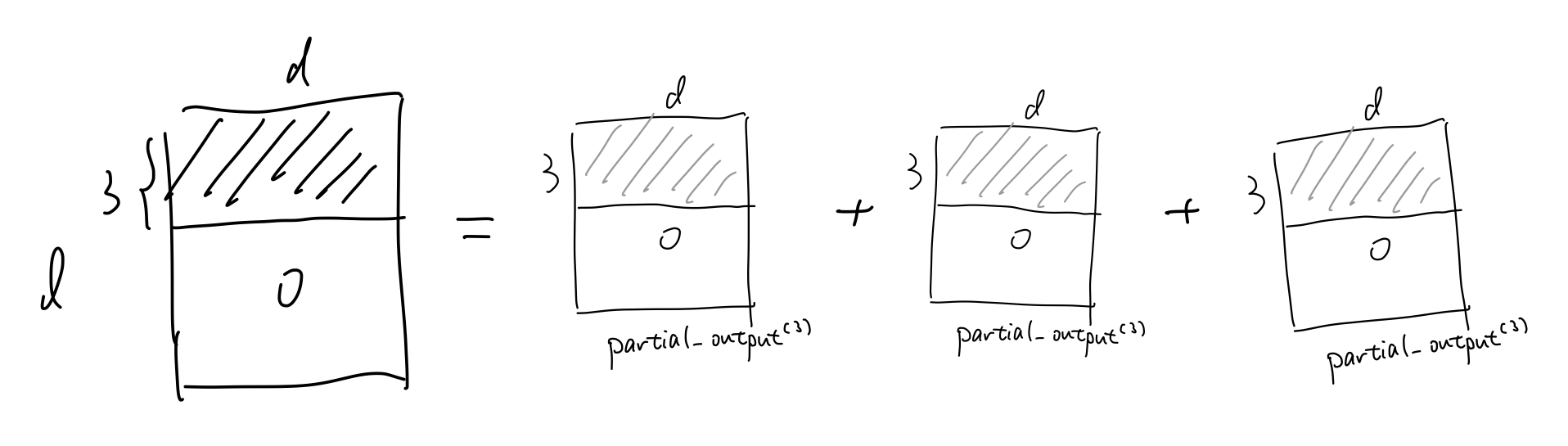
这样矩阵分块的思想,每个分块的计算完全在SRAM中完成,避免中间结果写回显存。
并且可以通过通过异步操作,在计算当前块时预加载下一块数据。减少了大量IO开销,最终达到2-4x speedup, 10-20x memory reduction。
Plug in softmax
现在我们要把attn_score=QKT的外层加上softmax函数,注意到softmax需要attn_score的一整行数据才能计算
而目前我们经过分块,往往无法在内存中储存完整的attn_score(因为如果储存了,那就又和直接计算没区别了),怎么办?
举个例子,如果我们要计算[5, 6, -1, 7, -4, 3]这个数组的softmax:
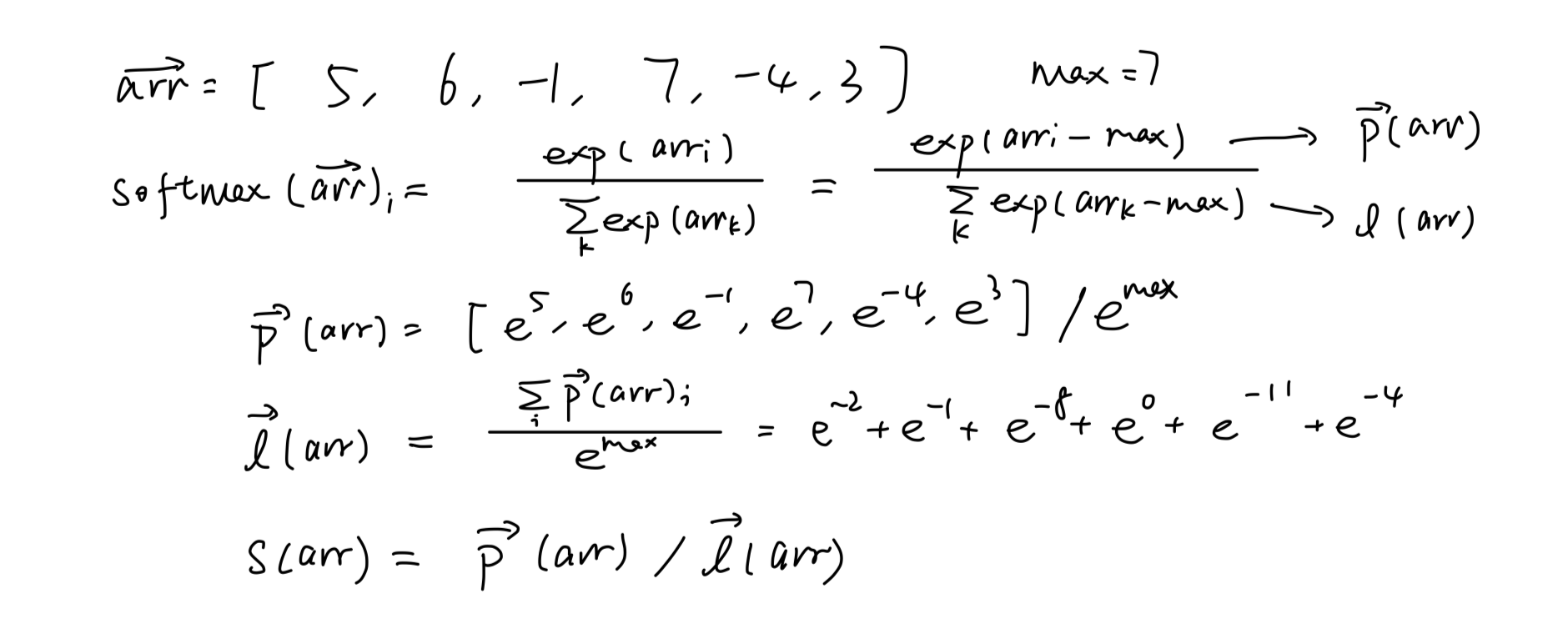
除去基本的exp计算,我们除以最大值以缓解数值爆炸带来的精度问题
如果要分别计算前半段和后半段:
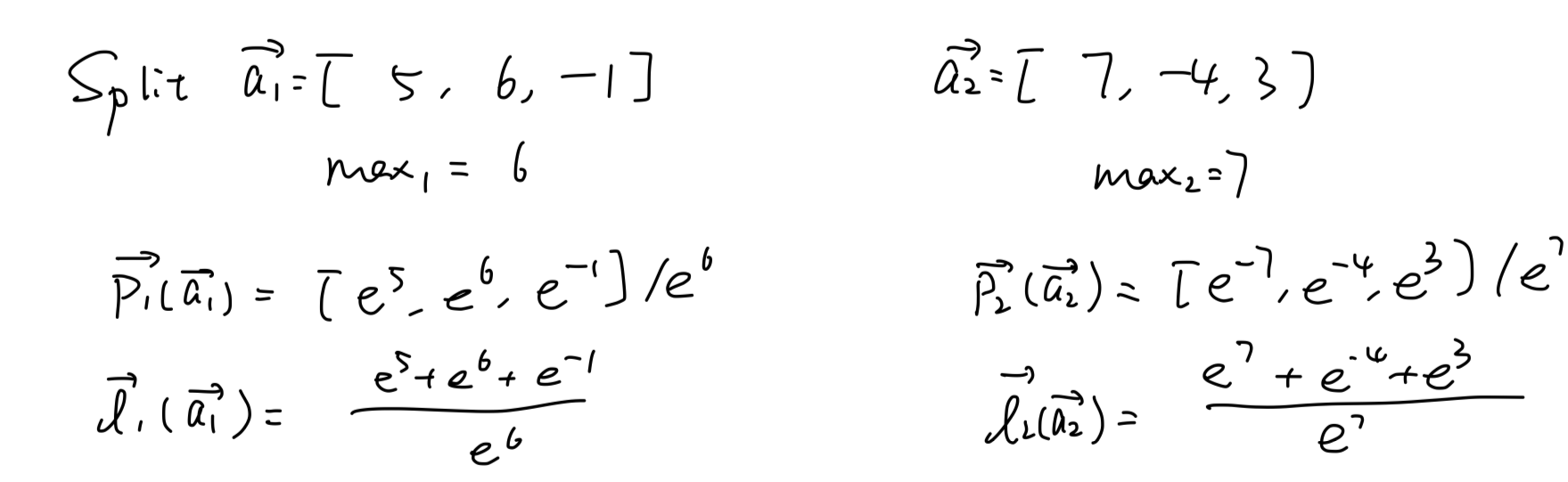
然后储存p1, p2, l1, l2, max1, max2:
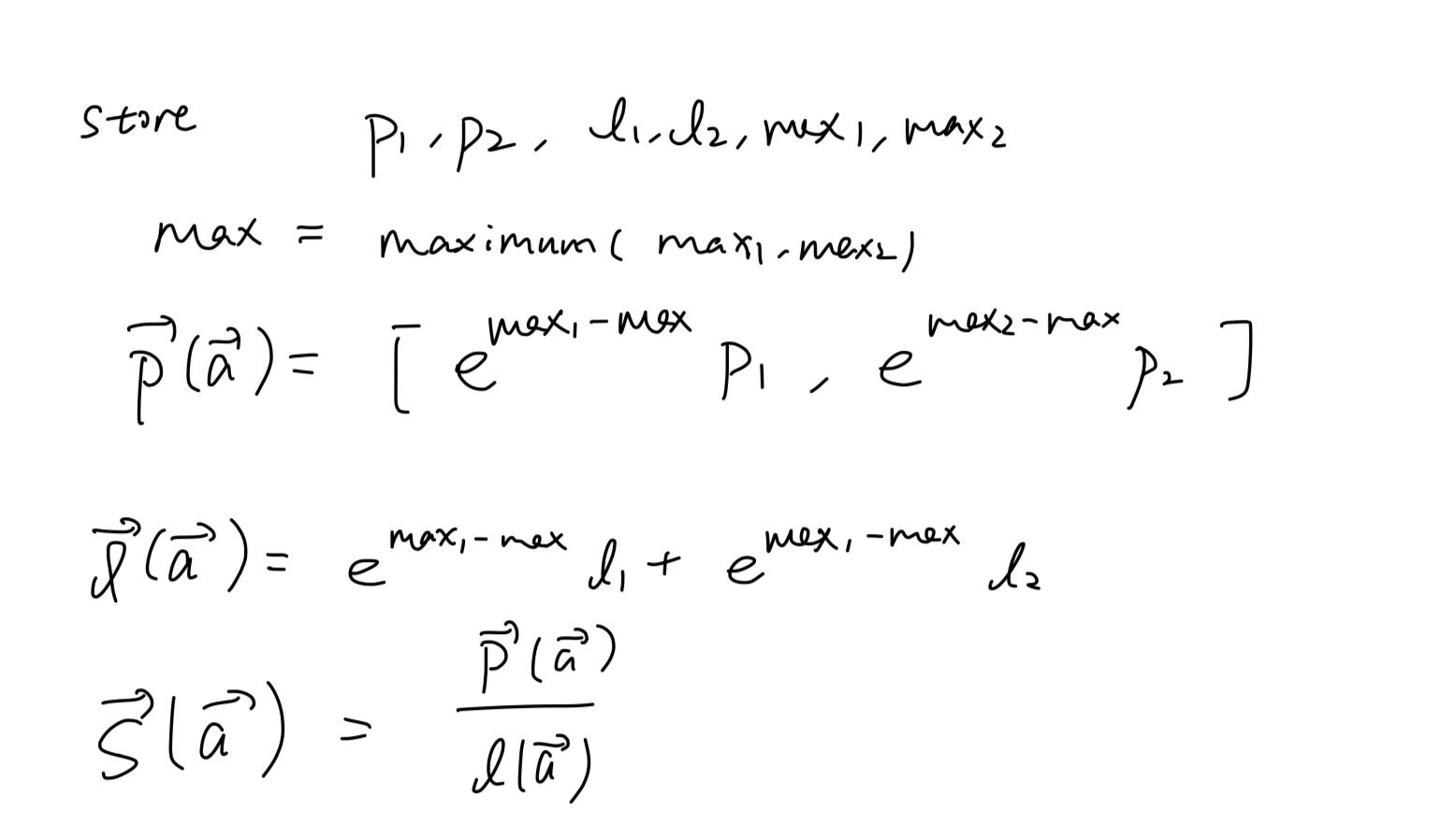
最后乘以max修正项得到全行的softmax S(a)。
其实本质就是一个数学上的小Trick,就是因为引入了减去exp(max)才导致有点小麻烦
如果计算机的世界没有精度问题,那么这个问题根本不需要讨论(储存p1, l1, ... pn, ln然后直接计算softmax)
Pseudocode

辅以论文中的Pseudocode供参考
This is brand new!
这篇文章的思路很新颖,以往关于attention的加速计算都在提升computation的速度,而本文的作者敏锐的观察到attention计算实际上是memory-bound! 进一步利用巧妙的方法将计算放到SBM上进行,完成了本作Flash Attention。
从2025年的视角来看,Flash attention已然是一个广泛使用的方法,时间和大量实践证明了其理论的正确性。
Result
文中提到Flash attention提供了up to 3× faster than the PyTorch implementation。
并且up to 20× more memory efficient than Pytorch的版本。
arXiv链接:https://arxiv.org/abs/2205.14135
Comment Area